LLM Powered Web Scraper
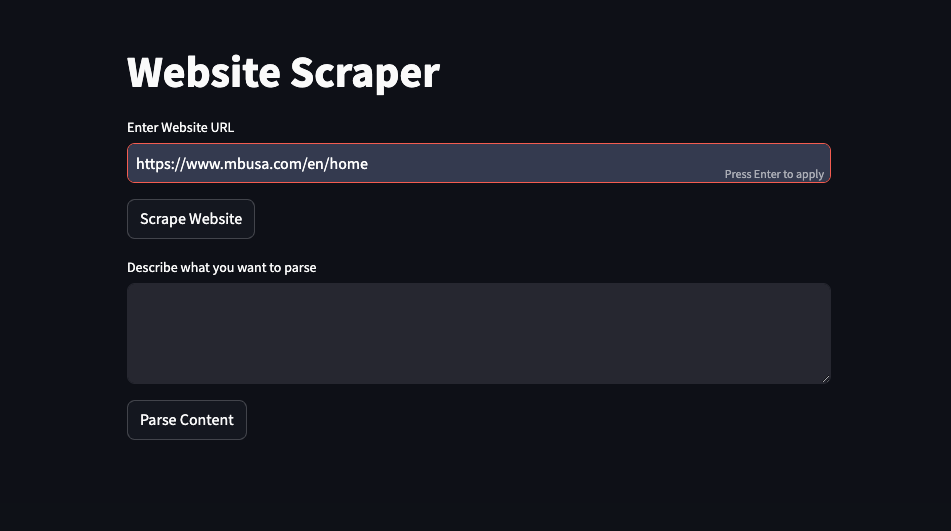
Back to PortfolioWeb-based application designed to scrape websites, clean the retrieved content, and extract specific information based on user input. Built with Streamlit, the application provides an intuitive interface where users can input a website URL and define the type of information they wish to extract. By leveraging web scraping techniques and the power of OpenAI's GPT-4 language model, the application transforms raw web content into meaningful, structured data.
Features
- Website Scraping: Input any website URL to retrieve its content using the ScraperAPI service, ensuring efficient and reliable scraping while handling various web protocols and potential obstacles like CAPTCHAs.
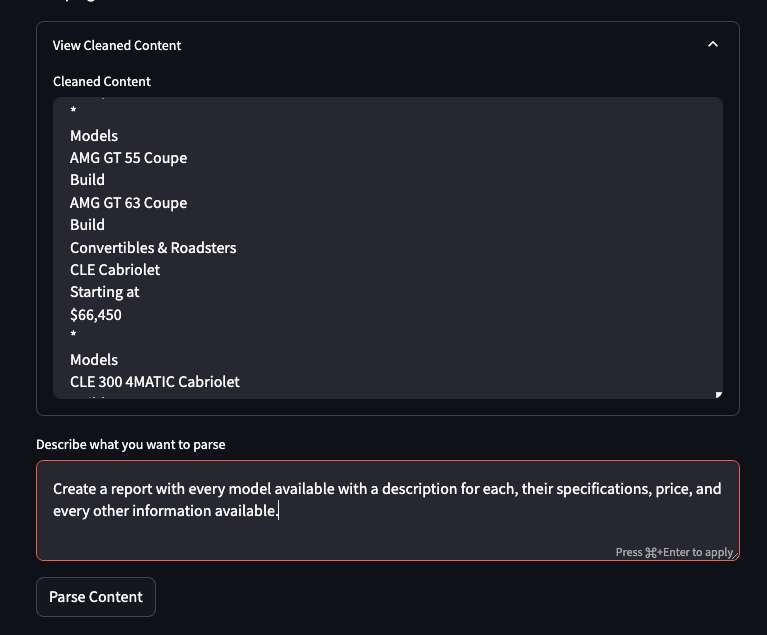
- Content Cleaning: Utilizes BeautifulSoup to parse and clean the scraped HTML content, removing unnecessary elements such as scripts and styles to focus on the main textual information.
- Custom Parsing: Allows users to define a custom description of the information they want to extract from the content. This description guides the parsing process to deliver tailored results.
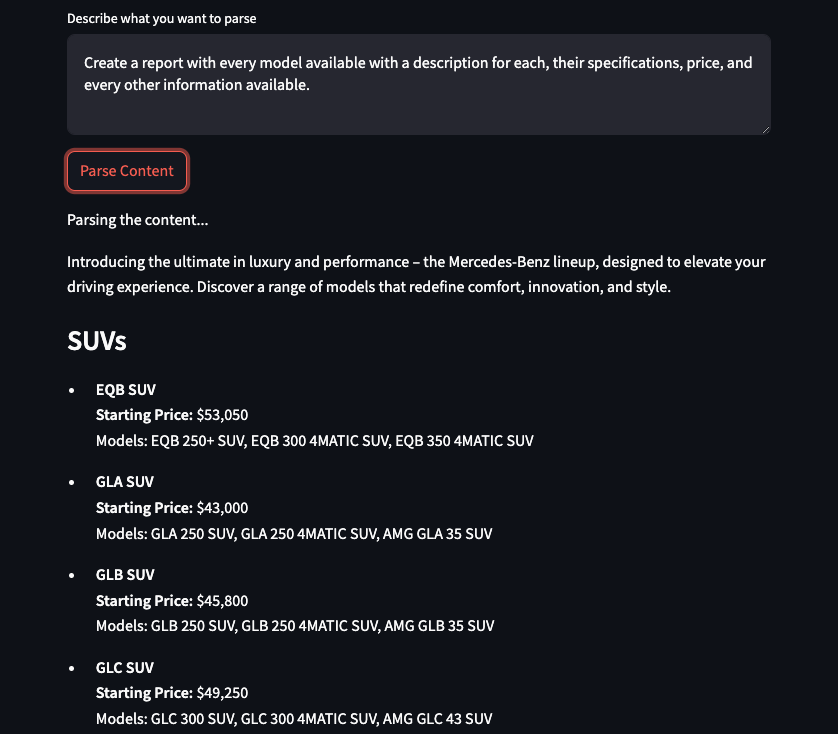
- GPT-4 Integration: Employs OpenAI's GPT-4 API to process the cleaned content in chunks, extracting relevant information as per the user's parsing description. The model interprets and generates human-like text, enhancing the quality of the extracted data.
- User-Friendly Interface: Built with Streamlit to provide a clean and interactive web interface that is easy to navigate, even for users without technical expertise.
Tools and Technologies Used:
- Python
- OpenAI API
- Streamlit
- BeautifulSoup
- ScraperAPI
- Requests